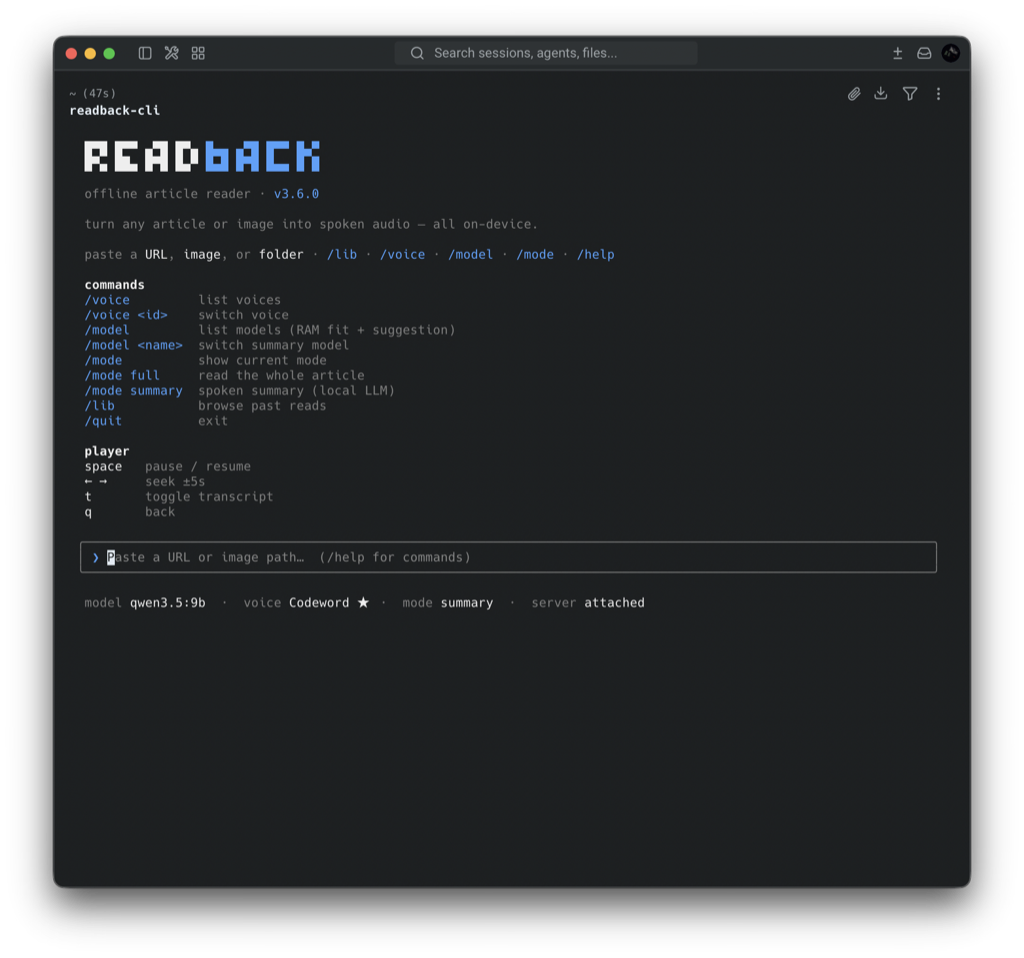
✓offline100% on-device — extraction, summary & speech run on Apple Silicon. No cloud, no API keys.
✓sourcesSnap a book, hear the chapter — read a URL, an image, or a folder of page photos; a local vision model OCRs them into one continuous read, and the tone adapts — a link sounds like an article, a book scan like a book.
✓voiceA voice worth listening to — CSM-1B neural TTS (Sesame); clone any voice from a short clip, or LoRA fine-tune.
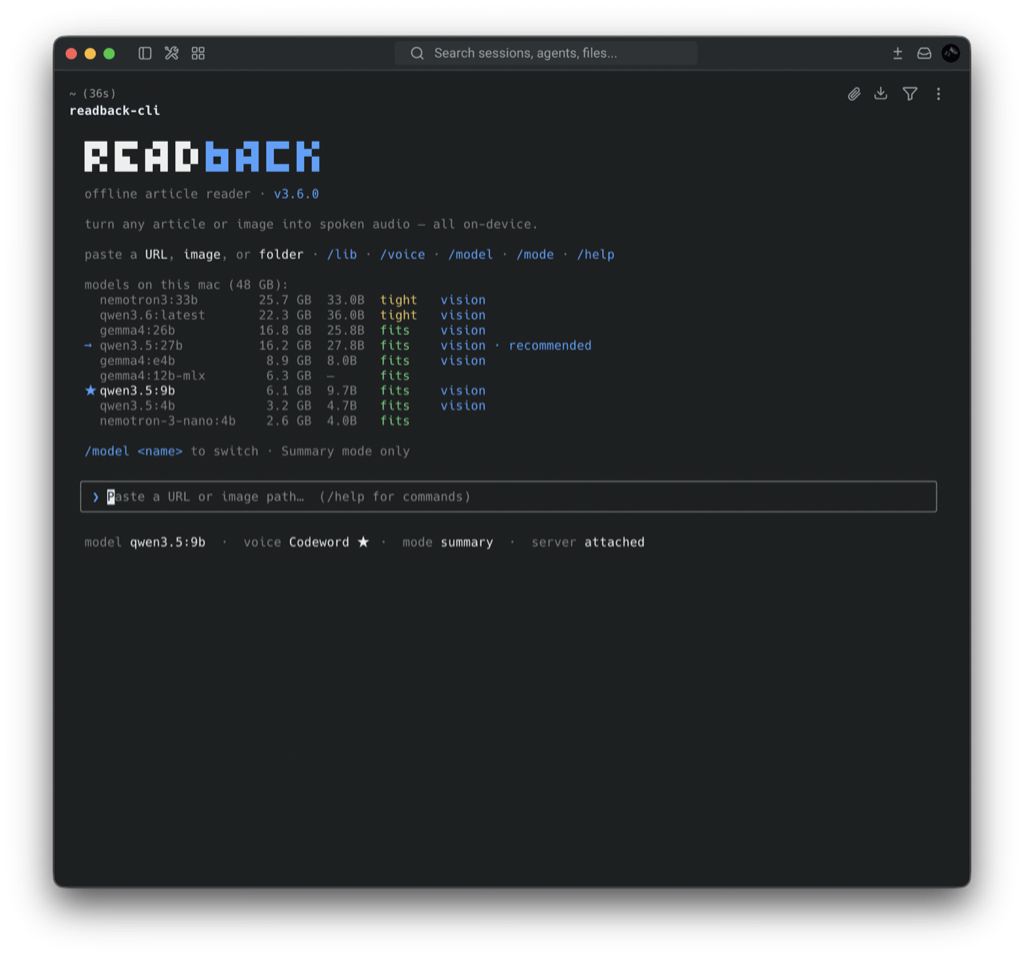
✓modesFull or Summary — verbatim, or a local Ollama LLM rewrites it as a spoken explanation; /model fits your RAM.
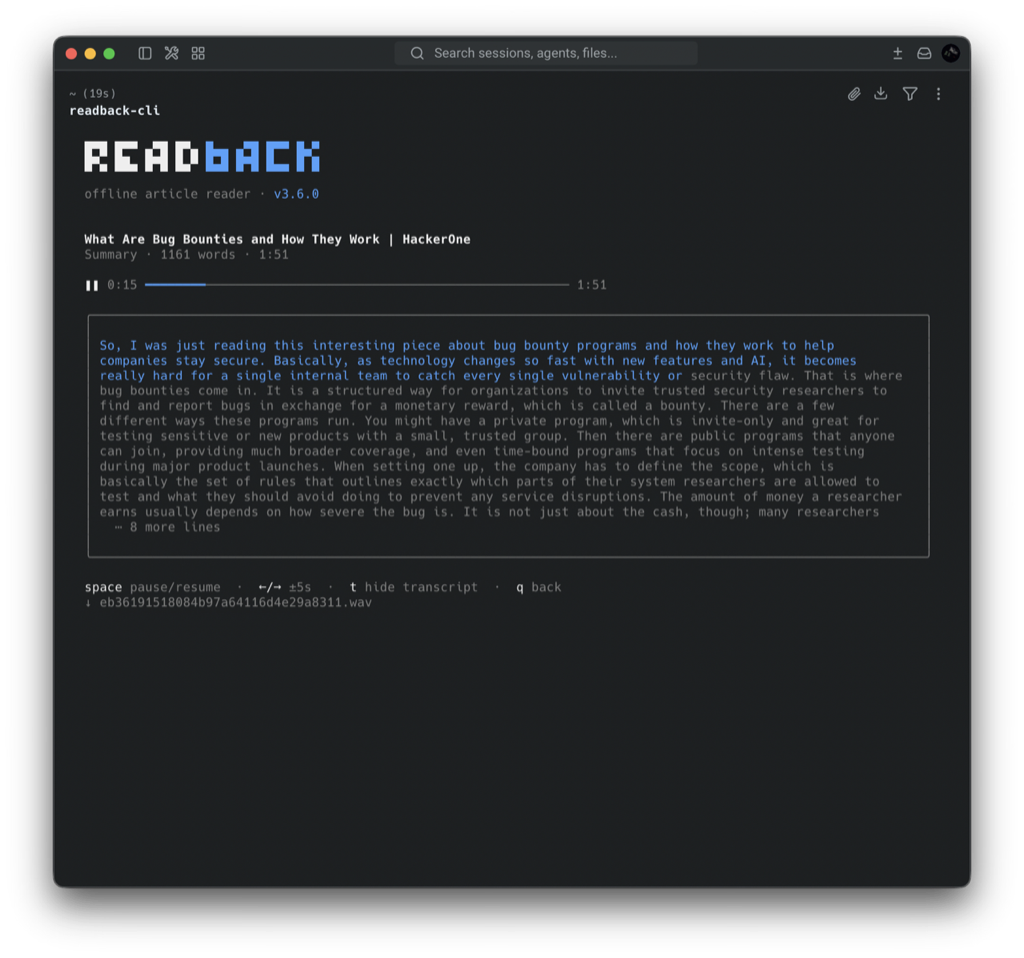
✓playerA real player — pause, seek ±5 s, and a transcript that highlights word by word — in your shell or the web dashboard.
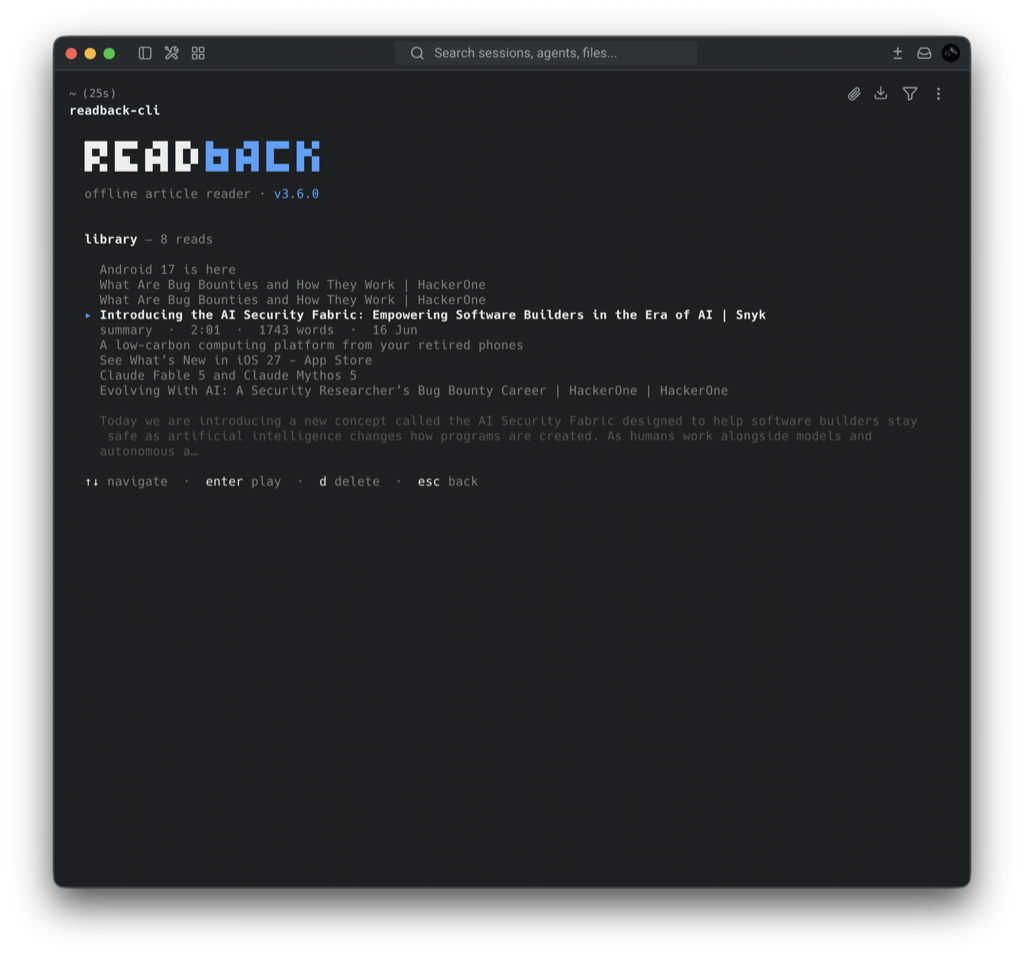
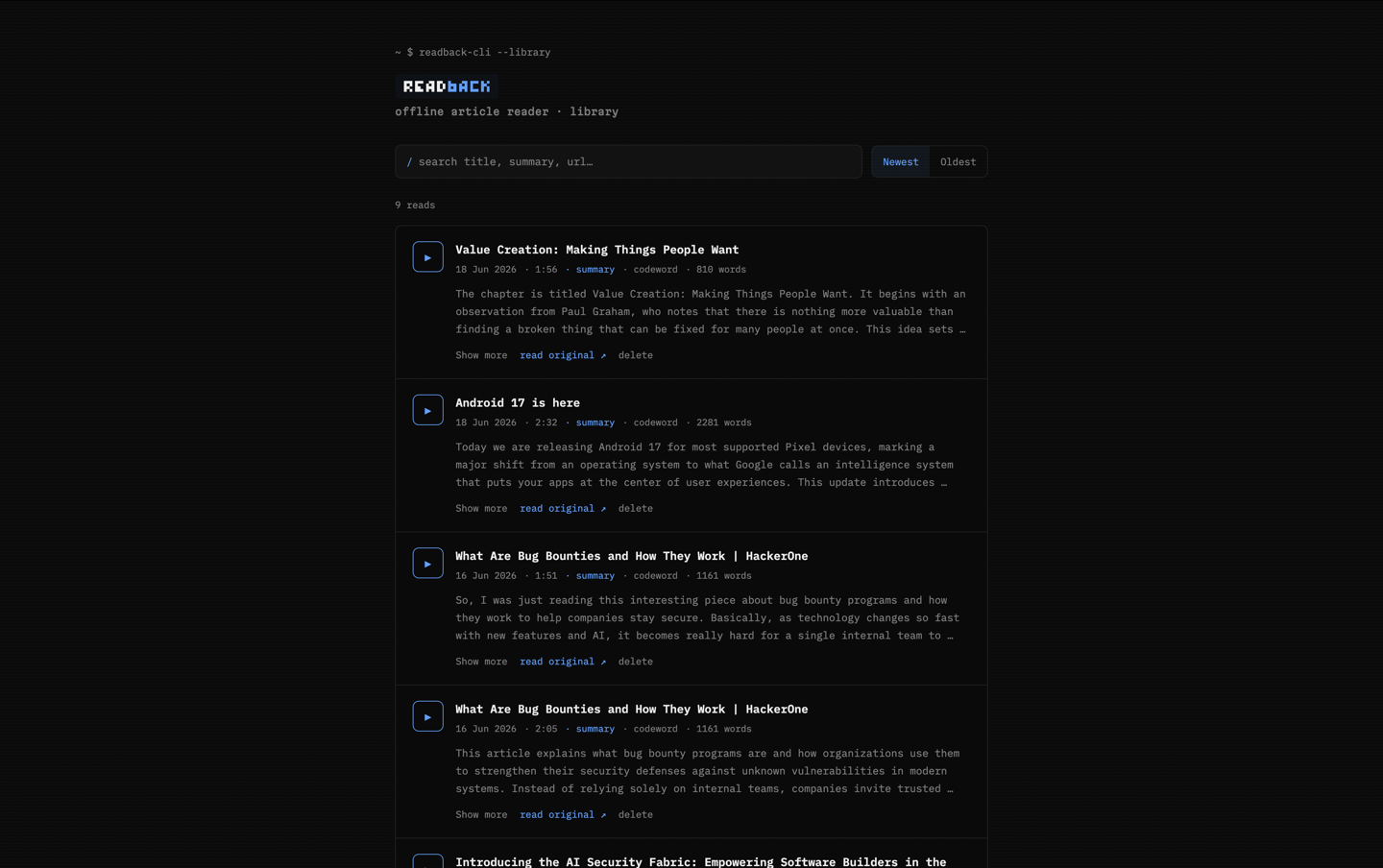
✓libraryReplay anytime — every read saved to a searchable SQLite library.
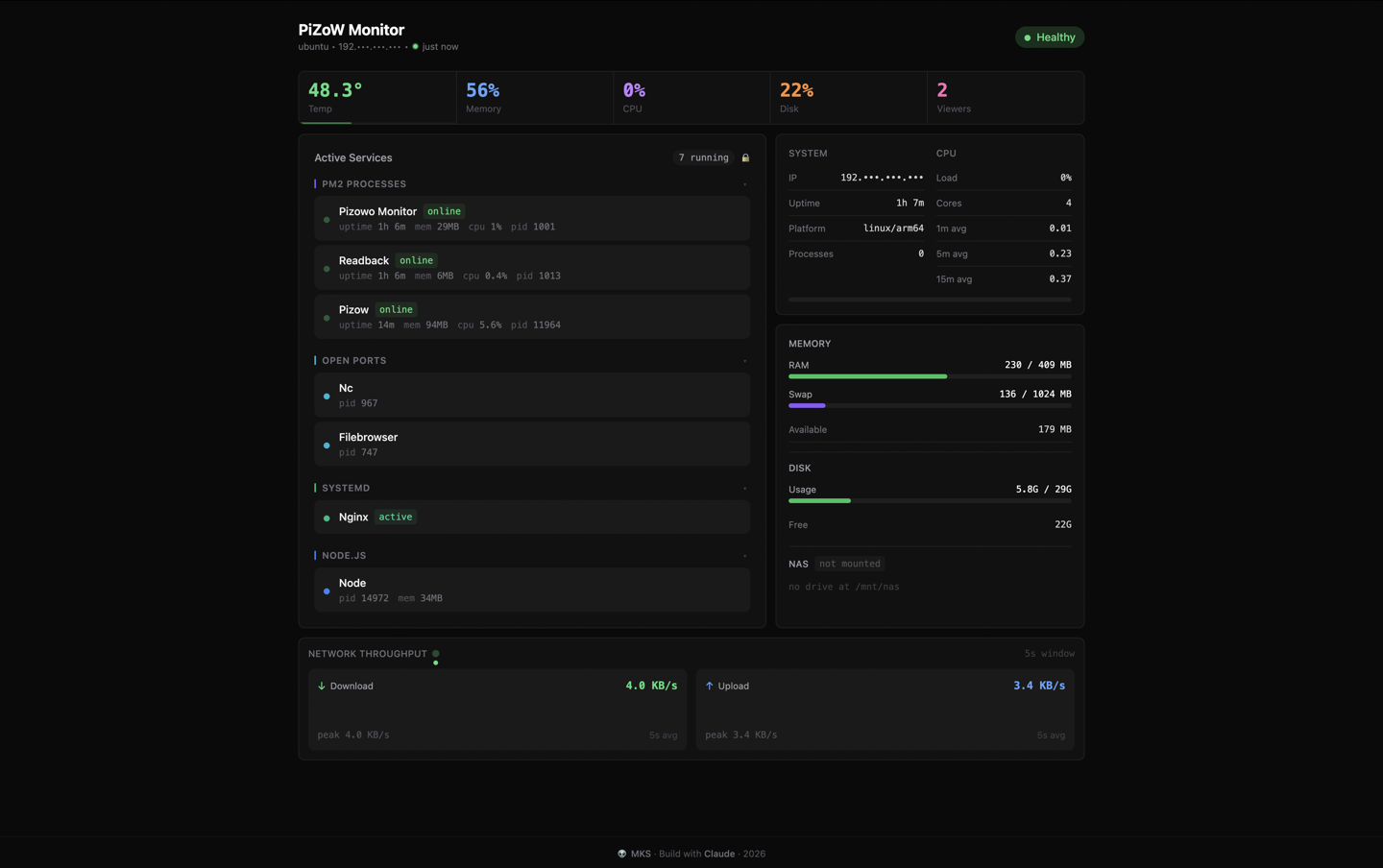
✓networkRun it on your network — deploy the dashboard to a Raspberry Pi (built on my PiZoW setup) and replay from any device at home.
7 features · 0 cloud calls · 0 API keys
Dive in
Install steps, the pipeline, the architecture, and the full build story —
all on GitHub.